Expressões regulares são padrões utilizados para encontrar sequências de caracteres em textos. Elas permitem a identificação de padrões específicos, como números de telefone, endereços de e-mail, CPFs e demais elementos.
Alguns conceitos importantes:
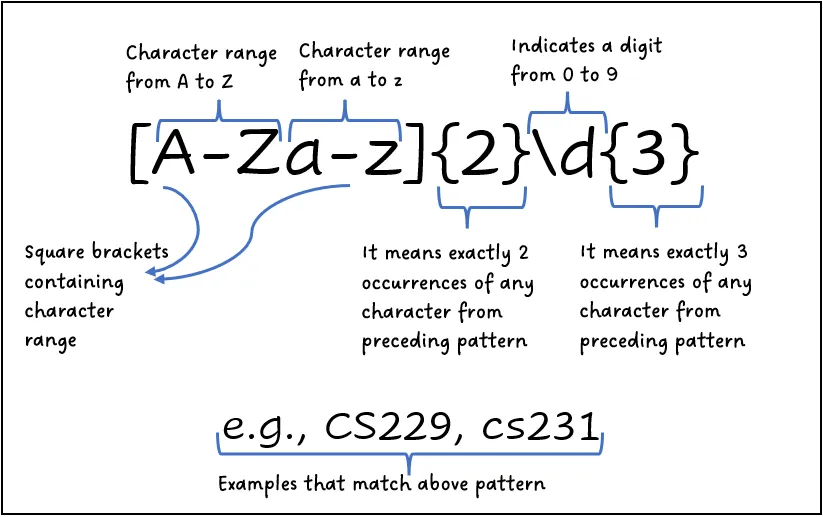
[]Um conjunto de caracteres. Observação: Dentro de um conjunto, os caracteres especiais normalmente não precisam ser escapados (Exemplo:.,+,-).?Quantificador em expressões regulares que indica que o padrão que o precede é opcional, ou seja, pode ocorrer zero ou uma vez.\bDenota uma fronteira de palavra, garantindo que o padrão comece e termine em uma fronteira de palavra (ou seja, não parte de um texto maior).\dMatch no qual os dígitos correspondem a números de 0–9.[a-zA-Z]Match para qualquer caractere entrea-z(minúsculo) ouA-Z(maiúsculo).
Exemplo de Uso de Regex para Encontrar Endereços de E-mail:
import re
texto = "joao teste1@gmail.co maria teste2@gmail.com adolfo teste3@protonmail.com"
padrao_email = r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}"
emails_encontrados = re.findall(padrao_email, texto)
print(emails_encontrados)
Output
['teste2@gmail.com', 'teste3@protonmail.com']
Neste exemplo, utilizamos uma expressão regular para encontrar todos os endereços de e-mail em um texto.
O padrão r”[A-Za-z0–9._%+-]+@[A-Za-z0–9.-]+.[A-Z|a-z]{3,}” é projetado para corresponder a uma ampla variedade de endereços de e-mail, incluindo domínios com três ou mais caracteres após o ponto.
Exemplo de Uso de Regex para Encontrar CPFs:
import re
lista_cpfs = [
"Fjwf: 000.000.000-11",
"rfjkfrfjk 239.458.234-10",
"ejkjefke 09812345691",
"cpf invalido 984395930111",
]
padrao_cpf = r"\b\d{3}\.?\d{3}\.?\d{3}-?\d{2}\b"
cpfs = []
for texto in lista_cpfs:
cpfs.append(re.findall(padrao_cpf, texto))
print(cpfs)
Output
[['000.000.000-11'], ['239.458.234-10'], ['09812345691'], []]
Neste exemplo, usamos uma expressão regular para encontrar CPFs em uma lista de strings.
O padrão r”.?.?-? corresponde a CPFs em diferentes formatos, incluindo aqueles com ou sem pontos e hífen.
